A new search engine created by ex-Googlers went public today: Cuil, pronounced, the site tells us, “cool;” it’s the Gaelic for “knowledge.” (And “hazel,” which seems less relevant.) The site seems to be suffering a bit from newcomer’s paralysis — the info page is currently not loading and some searches are timing out. Cuil claims to have indexed 120 billion pages, more than Google (which knows about over a trillion, but only indexes a small portion — though just how small, or large, Google’s not saying).
At first blush, I like Cuil’s layout. It presents results in two or three columns (you decide). Many results come with a small thumbnail image. In some cases, though, the image was of questionable relationship to the search; images were not present on the page you link to in a few cases. How images are applied is a mystery to me.
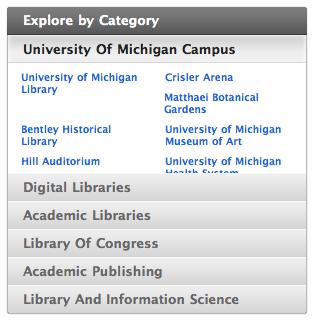
A search for “"University of Michigan Library"” (a phrase, including the quotes) finds it. It also presents “categories” of results on the right, with nicely bundled results.
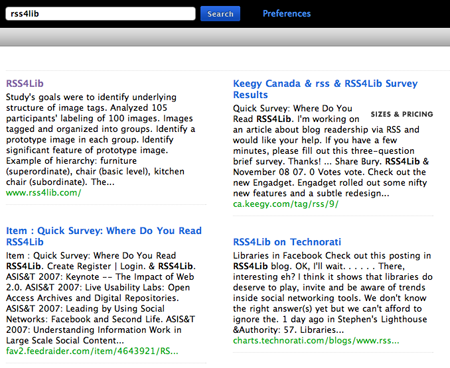
However, its currency is a bit poor, at least for low-traffic sites like RSS4Lib. A search at Cuil for RSS4Lib pulls up the main page as the first result, but the text shown dates from October 2007, quite a few posts ago).
There’s no apparent way to save a search alert (by email or RSS), which is unfortunate, as that seems to me to be just part of doing business. The interface, though, is quite clean and (at least for now) free of advertising. I’ll be curious to see how this new search tool develops.
For those of you who enjoying poring through your servers log files, Cuil is powered by the “twiceler” crawler you may noticed going through your site.
