A recent survey of WebJunction users showed some interesting statistics on use of various online tools by librarians (the write-up is at at “Library Staff Report Their Use of Online Tools“).
The trend from the survey indicates that social media (such as Facebook) is making inroads on email as a communication tool. Of particular interest to me is the finding that RSS feeds are used daily or weekly by only 24% of respondents and used never by 50%. Blogs are used daily or weekly by only 27%, and never by 40%.
I know I spend much less time reading blogs (and, as those of you who read RSS4Lib in its native blog for or via RSS might notice, writing for one). I do wonder how much RSS usage is un-noticed or un-recognized by respondents; as RSS (and XML in general) become the way data move, do its consumers care how the data appear where they’re consumed?
The survey results highlight differences between academic and public librarians (academic librarians are more likely to use online tools than their public counterparts) and a series of interesting differences between urban and rural librarians.
Category: Syndication
Farewell to Full-Text Feeds?
I’ve noticed over time that the number of people who ‘consume’ RSS4Lib on RSS4Lib.com has declined steadily over the years. Yet the number of feed subscribers is still steadily increasing (see today’s subscriber report and has recently broken 2000).
At the same time, few articles I post are read on RSS4Lib.com more than 100 times the day they are published, and most are viewed only a few times a day after that. (Selected items in the backfile, thanks to Google and Bing, get more traffic than recently published items once the new posts have aged a few days.)
I suspect this trend holds true across many blogs, whether they’re produced for love or money. (This one, to be clear, is not produced as a moneymaking venture.)
Some are suggesting that the days of full-text feeds are numbered (see “Say Bye Bye to Full RSS Feeds and RSS: What’s the Deal in 2010?,” as examples). I’m curious to know if these commercial prognosticators are correct — will bloggers tend to pull people toward the richness of their sites, even if there is no particularly strong monetary incentive to do so? Or will full-text feeds continue to be the way to go? I suspect a trend toward full text feeds (for blogs that are works of avocation) and snippet feeds (for those that are more vocational). And I’ll wager that this will break down (to oversimplify greatly) into an academic/commercial divide.
RSS Readers Not Dead Yet
ReadWriteWeb says, “5 Reasons Why RSS Readers Still Rock.” To summarize the post, here are the five reasons RSS readers are still relevant, according to RWW:
- Control over Information Flow
- Evolving User Interfaces
- Tracking Twitter
- Mobile News
- Categorized News
This post is in response to an earlier RWW post, “RSS Reader Market in Disarray, Continues to Decline,” which engendered a lively discussion in the comments.
Dave Winer, a pioneer of RSS, noted in the comments to the more recent post that RSS readers get one thing fundamentally wrong: they treat feeds like email by telling you how many unread messages you have and encouraging you to read each one. (I’m one of those weirdos who cannot stand having messages, especially unread ones, hanging around in my inbox. Having a growing tally of unread RSS items pushes me right over the edge and is the main reason I stopped consuming my feeds in my mail application.)
A number of automated tools offer filters for RSS feeds (many have been reviewed or discussed here). Most of them rely on explicit, user-defined keywords. Others, like Twitter, rely on one’s peers to identify the interesting stuff. However, I have yet to find a tool that offers the best of keyword filtering (letting through articles on topics that are of likely interest) while still surprising and delighting me with nearly, but not quite, on-topic posts. That’s an incredibly delicate, arbitrary, and undefinable balance to strike.
RSS and Atom Comparison
What’s the difference between RSS and Atom? Both are XML formats, both are in common use, and most people who read RSS feeds don’t need to know the technical differences between them. Atom was designed to resolve the incompatibilities among the various versions of RSS (0.92, 1.0, and 2.0) and is a bit more complex. It is also an Internet Engineering Task Force (IETF) specification, RFC4287. RSS 2.0’s specification is less formally reviewed and approved, but is still a standard.
If you’re curious about how they’re structured, here’s a page for you: Comparison of RSS 2.0 and Atom. The top of this page shows a schematic of each data format — showing each element and its children — and a sample file. This page goes on to a more technical discussion about generating each of these formats with JavaScript, but the schematics are handy and helpful.
Facebook Notes Redirects Your Feeds
I jumped on the Facebook bandwagon as it was pulling out of town and created a Facebook page for RSS4Lib (become a fan!). In the process, as I was adding the RSS feed for this blog using the Notes tool, I noticed something more than a little annoying: RSS feeds added to a Facebook page using Facebook’s Notes application are rewritten to drive all traffic from that version of the feed to Facebook, not your own site. While clearly in Facebook’s financial interest to bring more traffic to Facebook, they do so without explicit permission.
When you set up an RSS feed into Facebook notes, you are asked to agree to a brief terms and conditions that says, in its entirety, “By entering a URL, you represent that you have the right to permit us to reproduce this content on the Facebook site and that the content is not obscene or illegal.”
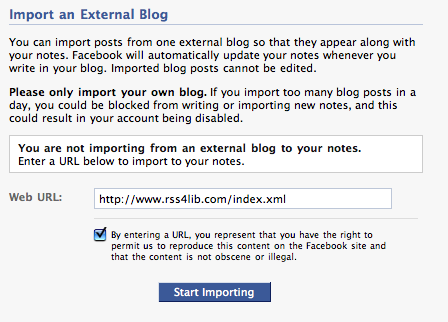
However, Facebook’s concept of “reproduce on the Facebook site” and mine are somewhat different. While I fully understood that my blog posts would be presented inside Facebook — as they are on the RSS4Lib Notes page, I am surprised that the associated RSS feed includes rewritten channel and item data. As an example, take a look at the feed’s channel data:
<channel> <title>RSS4Lib: Innovative Ways Libraries Use RSS's Facebook Notes</title> <link>http://www.facebook.com/notes.php?id=81126379633</link> <description>RSS4Lib: Innovative Ways Libraries Use RSS's Facebook Notes</description> <language>en-us</language> <category domain="Facebook">NotesFeed</category> <generator>Facebook Syndication</generator><docs>http://www.rssboard.org/rss-specification</docs> <managingEditor>http://www.facebook.com/pages/RSS4Lib-Innovative-Ways-Libraries-Use-RSS/81126379633</managingEditor> <webMaster>webmaster@facebook.com</webMaster> ... </channel>
The feed’s link goes to Facebook (http://www.facebook.com/notes.php?id=81126379633). That page provides reproductions of recent posts. Clicking on a post title, within Facebook, brings up that page in another Facebook page. There is a tiny link at the bottom of the page to “View original post”.
The individual items in the RSS feed are likewise rewritten:
<item> <guid>http://www.rss4lib.com/2009/05/feedmil_finds_feeds.html</guid> <title>Feedmil Finds Feeds</title> <link>http://www.facebook.com/note.php?note_id=82829822943</link> <description>Full Text of Post Goes Here</description> <pubDate>Wed, 13 May 2009 16:39:36 +0000</pubDate> <author>RSS4Lib: Innovative Ways Libraries Use RSS</author> <dc:creator>RSS4Lib: Innovative Ways Libraries Use RSS</dc:creator> <source url="http://www.rss4lib.com/index.xml">http://www.rss4lib.com/2009/05/feedmil_finds_feeds.html</source> </item>
They rewrite the link. They change the author from what it is in the original post, “rss4lib@gmail.com (Ken Varnum)”, assign a creator that is not the author cited in the original post, and link to an RSS feed as the source. (Facebook does display the URL of the post, but clicking it goes to the feed. Depending on your web browser, it may not be helpful behavior to get an XML file.) They don’t provide attribution for individual posts on the site.
The way Facebook is using my content does not fit my understanding of the Creative Commons “Attribution Non Commercial License” I have applied. Among other things, it states that:
- You must attribute the work in the manner specified by the author or licensor (but not in any way that suggests that they endorse you or your use of the work)
- You may not use this work for commercial purposes.
I’m willing to give on point 2 — yes, I understand that by reproducing my blog on Facebook’s site that I’m contributing to their commercial gain — but on point 1, I did not waive my right to appropriate attribution as specified in the license on the blog by agreeing to “reproduce” the blog on their site. If this is “remixing,” allowed in the Attribution Non Commercial license, requires that the licensee “takes reasonable steps to clearly label, demarcate or otherwise identify that changes were made to the original Work.” This has not been done.
This sort of misuse of content happens all the time, of course, but rarely so blatantly.
See Also
- RSS Feeds & Copyright (May 2008)
- Creative Commons and Bloggers (August 2008)
- Copyright, RSS, and Common Sense (September 2007)
Fair Use and Quoting Commercial Content
Say you’re blogging about a topic and you want to quote an excerpt of a commercial publication in your post. How much can you quote, verbatim, under the doctrine of “fair use“?
This is the subject of an article in Sunday’s New York Times: “Copyright Challenge for Sites That Excerpt.” Here’s how the Times article sums up the problem:
The legal disputes are emblematic of a larger question that has emerged from the Internet’s link economy. The editors of many Web sites, including ones operated by the Times Company, post excerpts from competitors’ content from time to time. At what point does excerpting from an article become illegal copying?
Courts have not provided much of an answer. In the United States, the copyright law provides a four-point definition of fair use, which takes into consideration the purpose (commercial vs. educational) and the substantiality of the excerpt.
[Yes, I’m aware of the irony of quoting an 88-word passage from an article about the dangers of quoting lengthy passages from commercial publications in a blog post.]
The concept of Fair Use is a tricky, and slippery one. The courts usually determine what is “fair” after the fact, when someone complains. A short excerpt that doesn’t reproduce the heart of the original almost certainly is fair use; a significant excerpt that reproduced the main point of the article probably is not. Reproducing the entire original clearly fails the text.
The culture of the blogosphere has been to define fair use quite broadly; the courts have rarely, if ever, had a voice in the matter. Yet. I suspect that, as the economic woes facing the corporate world drag on, commercial sites will increasingly perceive extensive quoting of their content on other sites as an economic problem. Whether such extensive quoting of published content has a real or imagined effect on revenue — and whether that effect is positive or negative — remains to be seen.
Related Posts
- AP, Bloggers, and Fair Use (June 2008)
- RSS Feeds & Copyright (May 2008)
Research Blogging — Connecting the Blogosphere to “The Literature” a Link at a Time
The Research Blogging web site is a nexus for peer-reviewed literature and serious academic blogging about it. (No, that’s not a contradiction in terms.) Research Blogging helps readers find critical analysis of scientific reporting by pulling these scholarly blog posts together. Many of these blog posts in reaction to published articles are written by experts in the field and can help you put the article in context. From the Research Blogging site:
Do you like to read about new developments in science and other fields? Are you tired of “science by press release”? ResearchBlogging.org is your place. Research Blogging allows readers to easily find blog posts about serious peer-reviewed research, instead of just news reports and press releases.
While the majority of posts indexed by Research Blogging are in the hard sciences, there are a reasonable number in the area of information and library science, broadly construed.
To join the commentary, you must register. Once you’ve done that, you get a code snippet to include in your posts that are about peer-reviewed articles. Research Blogging then adds your post to its index. Being a scholarly effort, there is peer review of posts indexed by the site — if other registered research bloggers feel your post does not follow the site’s guidelines, it is removed from the index. This keeps the content relevant to the site’s mission.
TicTOCs: It’s about Time
The JISC ticTOCS service has been formally launched after a significant trial period. (I first wrote about this service in July 2007.) The ticTOCs service aggregates the tables of contents (TOCs) from 11,470 scholarly journals from 422 publishers, for a total of 296,186 full-text articles. (Of course, you or your institution must have access to the full text of these journals to view them; the table of contents, though, is free.)
The idea behind ticTOCs is to make finding and subscribing to table of contents RSS feeds a simple process. This free service is long overdue. Getting lists of tables of contents from journal publishers is time-consuming, if it is possible at all. Being able to pull together feeds across journals in one OPML file will prove helpful to libraries wanting to deliver current awareness services, have more up-to-date subject guides (with a list of recent articles in that topics ‘hot’ journals), or to augment catalog records.
The site lets you identify journals of interest by topic, by title, or by publisher, subscribe to their tables of contents (the “TOCs”) by checking (“ticking”) a box, and then getting an aggregated feed of articles and abstracts to review. You can add all journals matching a search (subject, title word, or publisher) to your profile with a single click, or add individual titles.

You can export the subscription list of tables of contents as an OPML file to add to your favorite reader. For example, here is an OPML file of the 25 journals in the Computers — Internet category.
TicTOCs display each journal with its title, the standard icon for the RSS feed, and a menu to add that feed to either Bloglines or Google Reader. Articles are shown by title; a link at the top of the display allows you to show the full abstract provided by the publisher. And each article includes a link to add the citation to RefWorks.

TicTOCs also opens the door to other advanced services. For one example, once you have an OPML file for the RSS feeds for a group of journals, that list of feeds could be run through Yahoo! Pipes or other similar tool to filter for keywords. For another, the OPML file from ticTOCs could be edited to redirect all full-text links through the library’s proxy server, allowing that library’s users to get to the full text articles without any hassle at all.
Future developments I, for one, would like to see include (of course) more publishers — where’s Elsevier — and a simple way to query ticTOCs with a journal’s ISSN or EISSN and get back the canonical RSS feed. Such a service would let libraries more easily add an RSS feed for a journal to that journal’s entry in the local library catalog. It would also be helpful, at an institutional level, to have automatic rewriting of full-text URLs in table of contents feeds that included the library’s proxy server.
This service will save librarians time and, more importantly, save patrons time.
Related Articles
Correction
There are, in fact, 1870 Elsevier journal titles in ticTOCs — thanks to Roddy MacLeod for pointing out my error.
Updated 12 Feb 2009
For you programmers out there, ticTOCs now offers a downloadable file of journal titles, ISSNs, and RSS feed URLs. Not quite an API, but a good start. See the ticTOCs news site for details and or get the ticTOCs data set for yourself.
Bloglines Update
There’s been a lot of discussion (see TechCrunch, What I Learned Today, and Law.Librarians, among others) about Bloglines and the problems they’ve been having. I noticed today that Bloglines has returned to the status quo ante — RSS4Lib’s subscriber numbers, as inaccurate and wonky as they may be, have returned to where they were before I noticed the precipitous drop. Looking at my log files, I see that the Bloglines crawler now reports that I have 799 subscribers to the RSS feed (and 56 to the Atom). That actually represents growth over the last consistent numbers Bloglines provided via the crawler and, not unusually, a few more than Bloglines reports on its web site (its Beta site is more up-to-date, reporting the same 799 RSS feed subscribers as its crawler does).
Bloglines posted on its technical blog yesterday a brief note about the outage. It was Apple-esque in the level of details — it offered none — other than to say that the problem was fixed:
Some folks might have noticed that specific feeds were not updating recently on Bloglines, and we wanted to update you and fill you in on whatâs been going on. We have figured out what the glitch has been. Over the weekend, a fix was released on Bloglines to resolve the issue. All feeds should now be updating and back to normal. If you’re still experiencing problems you can report a stuck feed.
I still prefer Bloglines to Google Reader (call me old-fashioned), but was about to make the leap. I’m pleased the Bloglines is still alive and keeping their crawlers and index going. Google needs the competition — even if it’s not as serious as it could be.
Liability Insurance for Bloggers
With the rise of blogging as a recognized form of journalism “has come greater scrutiny and the inevitable rise in legal threats facing bloggers,” says David Cox of the Media Bloggers Association (MBA), a not-for-profit, non-partisan organization supporting the development of blogging and citizen journalism. The MBA has recently announced a program to offer “liability insurance program for bloggers which provides coverage for all forms of defamation, invasion of privacy and copyright infringement or similar allegations arising out of blogging activities.”
As bloggers take up larger roles in journalism, public commentary, and social discourse, the individuals and organization they write about are increasingly paying attention. The risks of being accused of libelous, defamatory, or other language are the same as in any other media; the world is now paying more attention. The MBA now offers an online course, “Online Media Law: The Basics for Bloggers and Other Online Publishers,” without charge. Upon completing the course, students are offered the opportunity to join the MBA and then to purchase (at a discount) the liability insurance. Anyone who has taken the course has access to directories of attorneys specializing in online libel cases.
Is it worth the cost of an MBA membership ($25/year) and insurance (I could not find details of the insurance cost on the MBA site) to mitigate against what I suspect is a small risk for me? Probably not, in my case. The more controversial a blogger’s posts, though, the more likely it is that someone might find them legally troublesome (and not just annoying).
Related Post
RSS and Legal Liability (4/24/2008)
Disclaimer: I have no affiliation whatsoever with the Media Bloggers Association.
Via RSS Blog.