I jumped on the Facebook bandwagon as it was pulling out of town and created a Facebook page for RSS4Lib (become a fan!). In the process, as I was adding the RSS feed for this blog using the Notes tool, I noticed something more than a little annoying: RSS feeds added to a Facebook page using Facebook’s Notes application are rewritten to drive all traffic from that version of the feed to Facebook, not your own site. While clearly in Facebook’s financial interest to bring more traffic to Facebook, they do so without explicit permission.
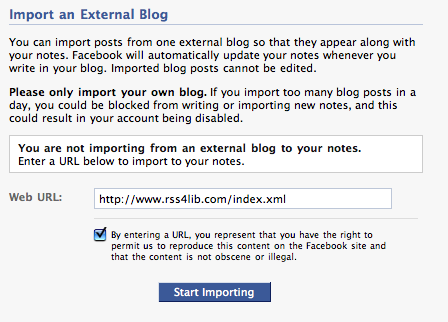
When you set up an RSS feed into Facebook notes, you are asked to agree to a brief terms and conditions that says, in its entirety, “By entering a URL, you represent that you have the right to permit us to reproduce this content on the Facebook site and that the content is not obscene or illegal.”
However, Facebook’s concept of “reproduce on the Facebook site” and mine are somewhat different. While I fully understood that my blog posts would be presented inside Facebook — as they are on the RSS4Lib Notes page, I am surprised that the associated RSS feed includes rewritten channel and item data. As an example, take a look at the feed’s channel data:
<channel>
<title>RSS4Lib: Innovative Ways Libraries Use RSS's Facebook Notes</title>
<link>http://www.facebook.com/notes.php?id=81126379633</link>
<description>RSS4Lib: Innovative Ways Libraries Use RSS's Facebook Notes</description>
<language>en-us</language>
<category domain="Facebook">NotesFeed</category>
<generator>Facebook Syndication</generator><docs>http://www.rssboard.org/rss-specification</docs>
<managingEditor>http://www.facebook.com/pages/RSS4Lib-Innovative-Ways-Libraries-Use-RSS/81126379633</managingEditor>
<webMaster>webmaster@facebook.com</webMaster>
...
</channel>
The feed’s link goes to Facebook (http://www.facebook.com/notes.php?id=81126379633). That page provides reproductions of recent posts. Clicking on a post title, within Facebook, brings up that page in another Facebook page. There is a tiny link at the bottom of the page to “View original post”.
The individual items in the RSS feed are likewise rewritten:
<item>
<guid>http://www.rss4lib.com/2009/05/feedmil_finds_feeds.html</guid>
<title>Feedmil Finds Feeds</title>
<link>http://www.facebook.com/note.php?note_id=82829822943</link>
<description>Full Text of Post Goes Here</description>
<pubDate>Wed, 13 May 2009 16:39:36 +0000</pubDate>
<author>RSS4Lib: Innovative Ways Libraries Use RSS</author>
<dc:creator>RSS4Lib: Innovative Ways Libraries Use RSS</dc:creator>
<source url="http://www.rss4lib.com/index.xml">http://www.rss4lib.com/2009/05/feedmil_finds_feeds.html</source>
</item>
They rewrite the link. They change the author from what it is in the original post, “rss4lib@gmail.com (Ken Varnum)”, assign a creator that is not the author cited in the original post, and link to an RSS feed as the source. (Facebook does display the URL of the post, but clicking it goes to the feed. Depending on your web browser, it may not be helpful behavior to get an XML file.) They don’t provide attribution for individual posts on the site.
The way Facebook is using my content does not fit my understanding of the Creative Commons “Attribution Non Commercial License” I have applied. Among other things, it states that:
- You must attribute the work in the manner specified by the author or licensor (but not in any way that suggests that they endorse you or your use of the work)
- You may not use this work for commercial purposes.
I’m willing to give on point 2 — yes, I understand that by reproducing my blog on Facebook’s site that I’m contributing to their commercial gain — but on point 1, I did not waive my right to appropriate attribution as specified in the license on the blog by agreeing to “reproduce” the blog on their site. If this is “remixing,” allowed in the Attribution Non Commercial license, requires that the licensee “takes reasonable steps to clearly label, demarcate or otherwise identify that changes were made to the original Work.” This has not been done.
This sort of misuse of content happens all the time, of course, but rarely so blatantly.
See Also
")
")
")