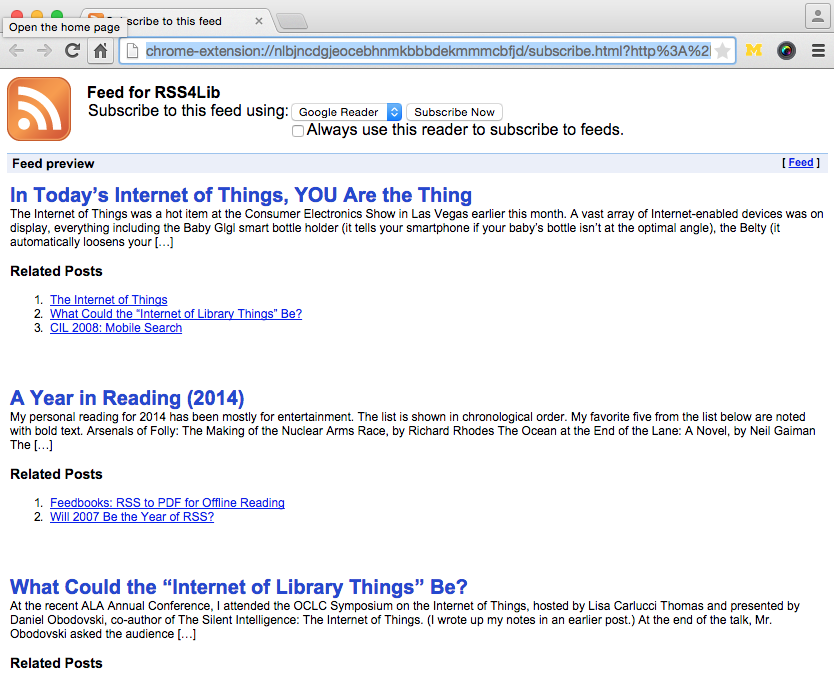
RSS Mixer, a recently released as an “alpha”, lets you create an account, input one or more RSS feeds, and gives you a combined output. Once you’ve set up an account (using OpenID or a one-off account at the site), entering feeds to mix is straightforward. The user interface is available in eight languages (there’s a language link in the site’s footer). Choices include German, English, Spanish, French, Russian, and Chinese.
Mixed feeds can be tagged and shared — there are built-in widgets for mobile versions, creating web widgets, emailing a mixed feed to a friend, and exporting a mix as an OPML file, in addition to the version viewable on the RSS Mixer site — for example, an ego search for RSS4Lib.
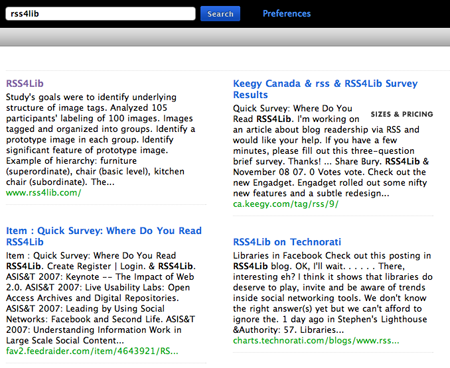
One thing I noticed is that sorting in mixes is odd. In the above two-feed mix (comprised of RSS4Lib’s RSS feed and a Technorati search feed for “rss4lib”), an RSS4Lib entry is sometimes followed by one or more posts discovered by Technorati about that particular entry. Other times, the Technorati post comes first. In all cases, though, the RSS4Lib entry was posted before anyone could comment on it — sorting should be consistent, whatever the algorithm is.
By further mashing up RSS Mixer’s output, it is possible to create a keyword search across multiple specific feeds. FeedSifter (reviewed here in July 2008) lets you searching a feed for one or more keywords. As a test of this, I used RSS Mixer to create a combined feed out of about 55 RSS- and library-related feeds. I then used FeedSifter to limit that to anything in that mixed feed that mentions metadata.
It would not surprise me if searching were on the drawing board for a future version of RSS Mixer, but there’s no indication of this functionality now.
RSS Mixer
Thanks to Suzanne for the tip about RSS Mixer.
")